1
2012
What is a Database Cluster?
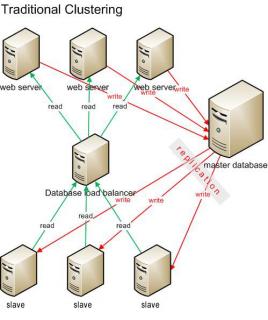
If it seems like you have a bunch of messy files and you have no idea about what step to take next, then you need to consider getting a database. The database will help you in storing and managing your files with the use of various commands such as SQL statements. With the use of the database, you’ll be able to organize your files according to clusters. This is called “database clustering”. How is database clustering relevant to the database management system? The database cluster […]
 An article by
An article by 
25
2012
What are Database Servers?
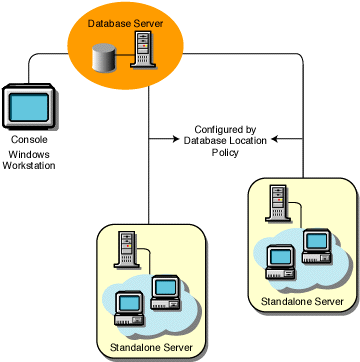
Database server is a program that connects the information stored in a database to other computers or computer programs. Most of the database management systems provide this type of function, while others count on the client-server model in order to access the database. The client-server model means that one computer, called the client, requests information from the server, which is the second computer. This is the type of model that most database servers use in order to function. There is also the master-slave model wherein […]
23
2012
What are Database Forms?
Database is a place to store data and has the capability of being accessed by other users whether they are at home, in the office, or anywhere. The databases are normally used by companies that are transacting with customers, businesses, and so on. Databases are great for storing information since they are organized and easy to access. It is also easy to use. Database is composed of forms, tables, rows, columns, fields, labels, and so on. These are necessary since these items are the ones […]
22
2012
What are Database Applications?
Database is the tool used to store essential information in a single system. The database is significant to those who want have large information on hand. With the use of any database, information will become organized and efficient. That’s why many databases are used to supplement learning in children, to aid in the sharing of files in networks, or to organize information for businesses. But what are its uses as well as its impact on manufacturing and businesses? Integration of the Database Applications Today, database […]
8
2012
What is a Database Migration?
The internet is a fast-paced world. In a place where there are literally hundreds of other competitors, you need to keep yourself updated. To be able to do this, you need to go hand in hand with the development of technology. There’s always a new version around the corner, so it’s important to keep your system updated to keep with everybody else. Whether you are a web owner, an online merchant or an e-mogul, it’s important to keep your database updated. Database Migration Database migration is […]
8
2012
What is Database Integration?

Today, we are now evolving into the world of more advanced technology. Many people in the line of business, education, medicine and other fields have taken on a new journey to make their jobs done more effectively and efficiently. The database is, by far, one of the best innovations made by man, but despite these advances in information technology, many users are still insatiable and would look for more ways to improve how things are usually done. That’s why database integration was conceptualized. With the […]
8
2012
What is Database Design?
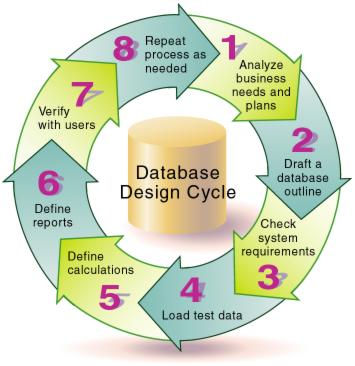
In simple terms, a database is your electronic data filing system that keeps all the records of your documents and files and helps you organize them as well for future use. A database is important in that it creates an organized system of keeping all your information in a single or multiple file which you can easily access whenever you need them. However, there’s a lot more to consider than just deciding to get a program to manage your database system for you. You database […]
4
2012
What is a Database Transaction?
When we are talking about database transaction, we are referring to a work or operation done within a management system of a database against another database using an understandable and reliable approach. This operation is done on its own without relying on another program. The transactions done in a database has two uses. First, the unit of work provided by the transaction produces accurate recovery of data whenever a failure occurs. It also keeps the information within the database accurate during the failure of the […]
10
2012
What is an Object Database?
Object database may also be referred to as an object-oriented database where the data is presented as an object, much like the ones used in an object-oriented program. Object database management systems or ODBMS are created by combining the capabilities of a database with the capabilities of an object programming language. The function of an ODBMS is to make the objects in a database look like objects for programming language in other object programming languages. The function of an ODBMS is to stretch the programming […]
10
2012
What is an OLAP Database?

OLAP stands for online analytical processing and is the process of easily acquiring selected data from a database. It also functions by displaying the information in different perspective depending on the user. If, for example, a user wishes to see a certain product and where it can be bought, OLAP will then generate different reports showing exactly what the user is looking for. This is due to the multidimensional capability of the OLAP, which, unlike the relational database, uses only two-dimensional interface. The beauty of […]
Advertisements
Recent Posts
- What is a Disaster Recovery Data Center
- What is a Relational Database?
- What is a Flat File Database?
- What is a DSN or Database Source Name?
- What is a Disaster Recovery Plan?
- What is an Open Source Database?
- What is Disaster Recovery?
- What is a Database Cluster?
- What are Database Servers?
- What are Database Forms?
Random Posts
- Disaster Recovery and Business Continuity Auditing
- What is Database Monitoring?
- What is a Data Dictionary?
- What is a Database Trigger?
- What is a Flat File Database?
- Disaster Recovery Solutions
- What is a Database Table?
- What is a PostgreSQL Database?
- What is an Embedded Database?
- What is Data Management?