25
2012
What is a Disaster Recovery Data Center

As corporate dependence on IT solutions continues to grow in the early 21st century, demand for reliable, cost effective disaster recovery data centers is expected to be one of the major growth markets for server and networking suppliers in their search for business continuity solutions in the event of unforeseen disaster striking. Disaster recovery has taken on more urgency with the growth of computer use within global corporations, and uptake in developing nations. Recent tragedies such as 9/11, North-Eastern power blackouts, or the Asian tsunami [...]
 An article by
An article by 
24
2012
What is a Relational Database?
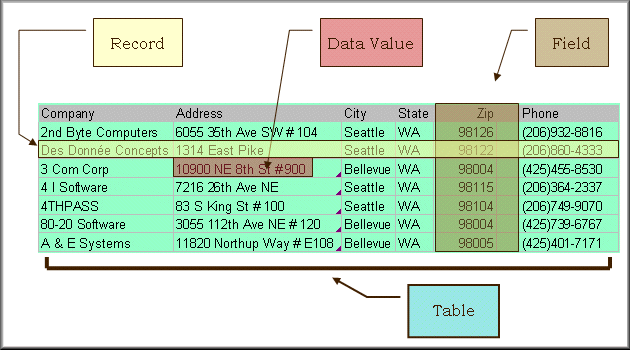
Majority of our population do not have much knowledge about computer and computer-related topics, but since the world is now going through a dramatic change because of technological updates, it is important that we become inclined to learn more about the concepts of information technology, and one of the most significant parts of information technology is the concept of database. This concept is widely used nowadays, especially in the field of business and education, but what is database and its significance to society? What is [...]
20
2012
What is a Flat File Database?
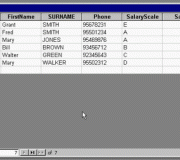
Databases have evolved as technology continues to develop. Contrary to popular belief, databases have existed before computers were built. The data was not recorded in a computer but with crude accounting systems which were used by banks. There are different ways to collect and organize data to form a database. One of the models used in early time before the age of computers were flat file databases. A flat file database encodes a table of data in different means as a plain text file. A [...]
19
2012
What is a DSN or Database Source Name?
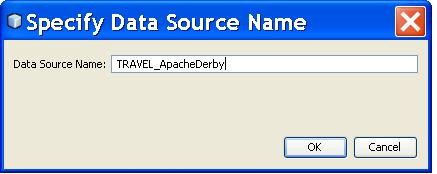
A data source name, also called the DSN, is a data structure that provides information on a certain database. This database usually includes an open database community server that it requires to function effectively. A data source name, which is usually embedded in a registry or a text file, includes information such as the name, the directory as well as the driver of the database. The DSN also includes the name and password of the user, which also depends on the DSN type. Most developer [...]
17
2012
What is a Disaster Recovery Plan?
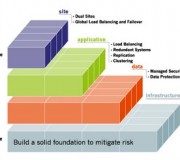
Disaster recovery planning is an IT function often involving a whole of business team whose role it is to anticipate disasters of any scale, determine the effects these would have on business continuity, and then create a set of policies and procedures for minimizing downtime and expediting recovery to pre-disaster levels. In smaller corporations the disaster recovery plan may in fact be just a sheets of paper listing steps to take when the unforeseen occurs, in fact, smaller organizations may be able to download disaster [...]
10
2012
What is an Open Source Database?

Open source is a kind of design where you can immediately access any kind of information from a set group with less hassle. This method has been closely studied by various companies to see whether this method can be used for their business. It has also reached technology in the form of open source database. The term itself, open source, has been gaining popularity with the development of technology, such as computers and Internet, which allows large numbers of users to tap into their sources [...]
4
2012
What is Disaster Recovery?
Disasters happen, be they manmade or natural, no corporation or government can ever assume their data and access to their data will be exempt from damage. Disaster recovery is their ability to recover electronic data and data processing to pre-disaster levels in the shortest possible time thru forward planning and setting policy objectives. Preparing for disasters and knowing that recovery will be possible requires careful analysis of the threats facing a corporation such as earthquakes, terrorism, hacking, staff strikes, electrical failure, even human error, and [...]
1
2012
What is a Database Cluster?
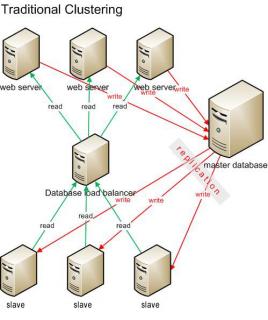
If it seems like you have a bunch of messy files and you have no idea about what step to take next, then you need to consider getting a database. The database will help you in storing and managing your files with the use of various commands such as SQL statements. With the use of the database, you’ll be able to organize your files according to clusters. This is called “database clustering”. How is database clustering relevant to the database management system? The database cluster [...]
25
2012
What are Database Servers?
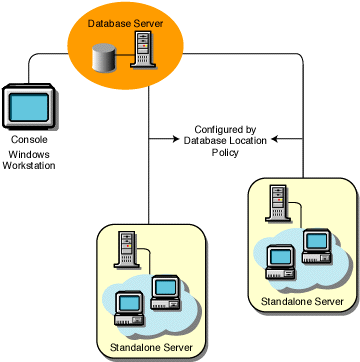
Database server is a program that connects the information stored in a database to other computers or computer programs. Most of the database management systems provide this type of function, while others count on the client-server model in order to access the database. The client-server model means that one computer, called the client, requests information from the server, which is the second computer. This is the type of model that most database servers use in order to function. There is also the master-slave model wherein [...]
23
2012
What are Database Forms?
Database is a place to store data and has the capability of being accessed by other users whether they are at home, in the office, or anywhere. The databases are normally used by companies that are transacting with customers, businesses, and so on. Databases are great for storing information since they are organized and easy to access. It is also easy to use. Database is composed of forms, tables, rows, columns, fields, labels, and so on. These are necessary since these items are the ones [...]
Advertisements
Recent Posts
- What is a Disaster Recovery Data Center
- What is a Relational Database?
- What is a Flat File Database?
- What is a DSN or Database Source Name?
- What is a Disaster Recovery Plan?
- What is an Open Source Database?
- What is Disaster Recovery?
- What is a Database Cluster?
- What are Database Servers?
- What are Database Forms?
Random Posts
- What is an Online Database?
- What is Database Administration and Automation?
- What is a Database Cluster?
- What are Database Models?
- What is a Database Schema?
- What is a DBA or Database Administrator?
- What is Database Monitoring?
- Disaster Recovery Software Options
- Importance of Database Backup
- Where to Get Disaster Recovery Training