1
2012
What is a Database Cluster?
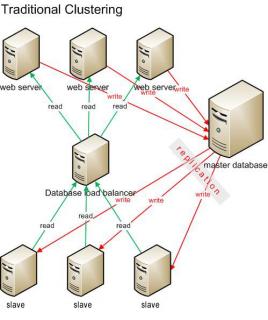
If it seems like you have a bunch of messy files and you have no idea about what step to take next, then you need to consider getting a database. The database will help you in storing and managing your files with the use of various commands such as SQL statements. With the use of the database, you’ll be able to organize your files according to clusters. This is called “database clustering”. How is database clustering relevant to the database management system? The database cluster […]
 An article by
An article by 
4
2012
What is High Availability?

In IT terms, high availability is the term used to describe a server or network, and by extension all of the constituent components, that is continuously available for data input, processing, and report querying. In it’s simplest sense, we see high availability in our everyday interactions on the web, it is very rare for the top 10 websites to be offline. The systems and protocols in place largely determine the success or not of a high availability goal, mostly because components fail randomly, and no […]
14
2012
What are High Availability Servers?

High availability servers a modern implementation of server hardware that are designed to extremely high fault tolerance levels to keep performing even in the event of a failed component, and are the latest buzzword in server technology with major CPU designers hailing the technology as the next evolutionary step. Traditionally, server hardware and software have been designed to optimize the functions of a single CPU controlling memory, storage, and input/output, leading to never satisfactory multitasking that has to a great extent been dependent on operating […]
13
2012
What are High Availability Clusters
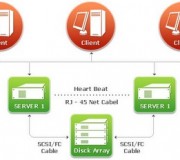
High availability clusters (HA clusters), also known as failover clusters, are a network of servers configured to operate as a single machine with data backups occurring in real time so that in the event of a failure in the network backup machines will take over seamlessly and continue to operate. High availability clusters are designed to operate automatically and not need the intervention of an IT support person to restart the network. A single server that fails results in downtime of the network, in some […]
11
2012
High Availability Architecture
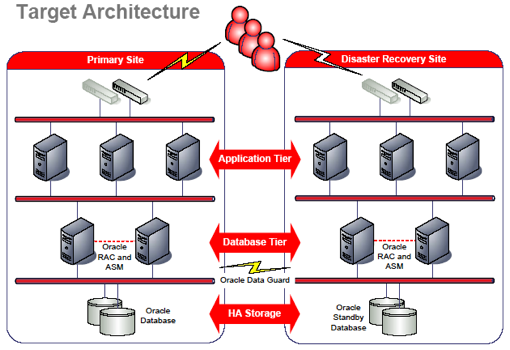
High availability networks are complex and costly systems to rollout with long planning timeframes and high expectations from users that the system will perform. To choose the correct hardware and software and the optimum network design IT administrators and their staff invest a considerable amount of time in analysis of corporate needs. Network architecture that is rated high availability needs to perform to very strict standards of uptime. Redundancy rather than being a stated goal becomes a necessary component of high availability networks, inherent in […]
11
2012
High Availability Solutions

High availability is no longer a luxury beyond the affordability of most corporations, in the 21st century it is now considered a requirement for almost all businesses regardless of industry and solutions are actively sought. Quite simply, a computer or server that fails might very well prevent the business from operating, and in today’s online world that may equate to significant lost revenue. Within select industries such as government, financial services, legal, or health and hospitals, downtime is simply not acceptable. High availability of service […]
Advertisements
Recent Posts
- What is a Disaster Recovery Data Center
- What is a Relational Database?
- What is a Flat File Database?
- What is a DSN or Database Source Name?
- What is a Disaster Recovery Plan?
- What is an Open Source Database?
- What is Disaster Recovery?
- What is a Database Cluster?
- What are Database Servers?
- What are Database Forms?
Random Posts
- What are Database Applications?
- What is Database Monitoring?
- What is Database Hosting?
- What is a DSN or Database Source Name?
- Database Architecture
- What is a Data Dictionary?
- What is a Database?
- What is a Database Migration?
- Remote DBA or Database Administration Services
- What is a Flat File Database?