1
2012
What is a Database Cluster?
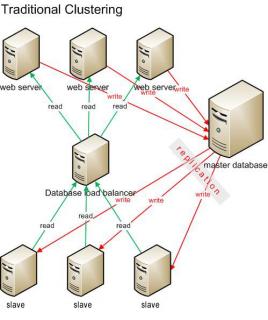
If it seems like you have a bunch of messy files and you have no idea about what step to take next, then you need to consider getting a database. The database will help you in storing and managing your files with the use of various commands such as SQL statements. With the use of the database, you’ll be able to organize your files according to clusters. This is called “database clustering”. How is database clustering relevant to the database management system? The database cluster […]
 An article by
An article by 
25
2012
What are Database Servers?
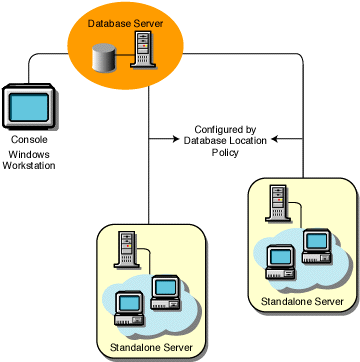
Database server is a program that connects the information stored in a database to other computers or computer programs. Most of the database management systems provide this type of function, while others count on the client-server model in order to access the database. The client-server model means that one computer, called the client, requests information from the server, which is the second computer. This is the type of model that most database servers use in order to function. There is also the master-slave model wherein […]
10
2012
What are Database Indexes?
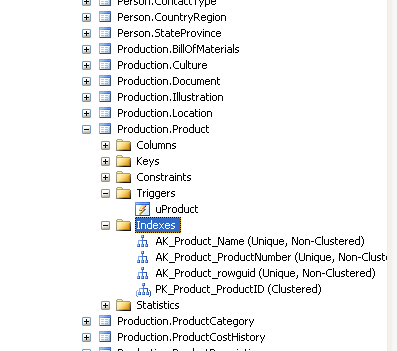
The database index is defined as a database structure whose primary function is to make the operations on a database table faster. Creating a database index requires one or a number of columns on a table for faster accessing of records in a database. Database indexes only occupy a small part of the disk memory since they only contain important key fields and discard the other fields within the table. This way, the index can be stored even though the database holds a large number […]
8
2012
What is a Database Migration?
The internet is a fast-paced world. In a place where there are literally hundreds of other competitors, you need to keep yourself updated. To be able to do this, you need to go hand in hand with the development of technology. There’s always a new version around the corner, so it’s important to keep your system updated to keep with everybody else. Whether you are a web owner, an online merchant or an e-mogul, it’s important to keep your database updated. Database Migration Database migration is […]
8
2012
What is a Distributed Database?
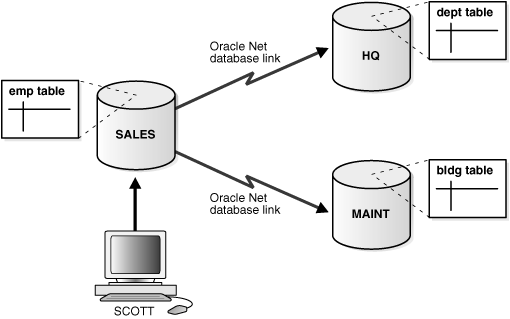
One of the exemplary models of database management systems is the distributed database. Distributed database is the database that is under the command of a central database management system in which certain storage tools are not installed in a single CPU. The distributed database is installed in multiple computers located in the same location or these computers are located in different locations but under interconnected computers. In a distributed database, data are shared through partition fragments, and these fragments can be produced. Moreover, distributed database […]
8
2012
What is Database Integration?

Today, we are now evolving into the world of more advanced technology. Many people in the line of business, education, medicine and other fields have taken on a new journey to make their jobs done more effectively and efficiently. The database is, by far, one of the best innovations made by man, but despite these advances in information technology, many users are still insatiable and would look for more ways to improve how things are usually done. That’s why database integration was conceptualized. With the […]
8
2012
What is Database Design?
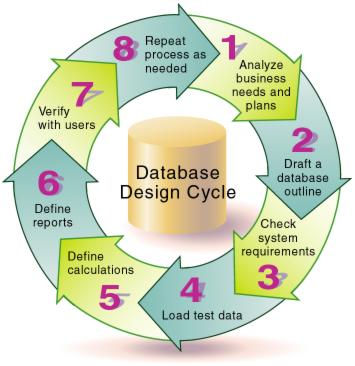
In simple terms, a database is your electronic data filing system that keeps all the records of your documents and files and helps you organize them as well for future use. A database is important in that it creates an organized system of keeping all your information in a single or multiple file which you can easily access whenever you need them. However, there’s a lot more to consider than just deciding to get a program to manage your database system for you. You database […]
4
2012
What is a Database Transaction?
When we are talking about database transaction, we are referring to a work or operation done within a management system of a database against another database using an understandable and reliable approach. This operation is done on its own without relying on another program. The transactions done in a database has two uses. First, the unit of work provided by the transaction produces accurate recovery of data whenever a failure occurs. It also keeps the information within the database accurate during the failure of the […]
15
2012
What is Database Normalization?

In terms of relational database design, database normalization is the process in which a database structure is free from any uncertainties like UPDATE, INSERTION and DELETION incidences. When this happens, the integrity of the data is at stake. That’s why, normalization was conceptualized. To be able to normalize a certain database, it should be designed in the third normal form. In the third normal form, all data will be secured, and only certain areas of the table are subjected to any change. Generally, a standard […]
21
2012
What is a Data Dictionary?
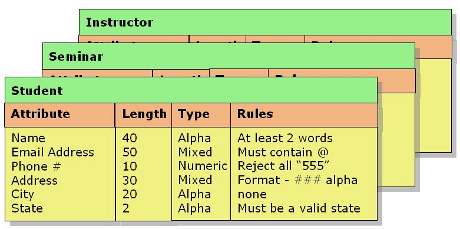
Because of the tremendous growth of multimedia applications, data can be transferred through various ways. Thus, data dictionary was conceptualized. Data dictionary is not your usually online database search engine, but this program supports the sharing of data from one country to another. Data dictionary, particularly its contents, is used to develop pdf files for data inputs on Excel templates. Data dictionary pioneered the notion on automated delivery of data from countries as well as the innovation of data delivery interface. The Terms Described and […]
Advertisements
Recent Posts
- Wie VIP Luck Deutschland digitale Glücksspieloptionen für deutsche Spieler bereitstellt
- Link Factory Sitewide Verification
- Link Factory Verification
- Wie Social Media unser Verständnis von großen Spielgewinnen beeinflusst
- Spinsy Casino im Internet: Vielfältige Spielautomaten und attraktive Bonusangebote
- Undresser.it.com Delivers Consistent Image Quality for AI Visuals
- Profitez des meilleurs jeux sur Nova Jackpot avec paiements rapides et sécurisés jouer au casino en ligne
- Mobiles Glücksspiel: Casino-Spiele und Wetten jederzeit unterwegs
- How to Discover Legitimate Casino Sites Not Registered with GamStop
- Why UK Players Opt for Non GamStop Casinos for Adaptable Gaming Options
Random Posts
- What is an Object Oriented Database?
- What is Database Security?
- What is a PostgreSQL Database?
- What is a Multimedia Database?
- What is a Disaster Recovery Data Center
- What is a Database Query?
- Free Database Software Options
- Why UK Gamers Choose Non GamStop Casinos for Unlimited Play
- What is a XML Database?
- Mostbet – Niy? Mostbet-d? Kiberidman Canl? M?rcl?ri Gülm?li v? M?ntiqlidir – Mostbet-d? Kiberidman Canl? M?rcl?ri üçün Add?mlar